Windowsで利用される文字コードは、多様な言語と文字セットに対応するため、複雑な仕組みを持っています。本稿では、Windowsにおける主要な文字コード、シフトJIS、Unicode、UTF-8などを解説し、それぞれの特性、互換性、そして潜在的な問題点について詳細に掘り下げます。特に、文字化けの原因と解決策、異なる文字コード間の変換方法に焦点を当て、Windows環境下での文字コードの適切な取り扱い方を理解する上で役立つ情報を提供します。開発者や一般ユーザーにとって、文字コードの知識は不可欠です。
Windows 文字コードの基礎知識
Windows は、世界中で広く使われているOSですが、その文字コードの扱いについては、やや複雑な側面があります。 日本語環境では特に、Shift-JIS、EUC-JP、UTF-8といった複数の文字コードが混在しており、開発者やユーザーにとって理解を要する部分です。 この複雑さは、歴史的な経緯や、互換性の維持といった様々な要因が絡み合っているためです。 例えば、古いシステムとの互換性を保つためにShift-JISが長く使われ続けてきた一方で、国際的な標準であるUTF-8の利用も近年増加しています。 そのため、Windows上で文字コードを正しく扱うためには、それぞれの文字コードの特徴を理解し、適切な設定を行うことが重要になります。 特に、ファイルの保存時や読み込み時には注意が必要で、文字化けが発生しないよう、適切な文字コードを指定しなければなりません。 また、プログラムを作成する際には、使用する文字コードを明確に指定し、文字コード間の変換処理を適切に行う必要があります。 Windowsにおける文字コードの理解は、システム全体の安定性やデータの整合性を保つ上で不可欠です。
Shift-JIS の特徴と利用例
Shift-JIS は、日本語環境で広く利用されてきた文字コードです。JIS X 0201 と JIS X 0208 の漢字を収容しており、比較的コンパクトなコード体系です。しかし、可変長の文字コードであるため、文字列の処理が複雑になる場合があります。 また、UTF-8 との互換性がないため、国際的なデータ交換には注意が必要です。 現在でも多くの既存システムで利用されているため、理解しておくことが重要です。特に、古いシステムとのデータ連携を行う際には、Shift-JISの扱いを理解しなければなりません。
EUC-JP の特徴と利用例
EUC-JP は、EUC(Extended Unix Code) の日本語版です。Shift-JISと同様に日本語の文字を扱うことができますが、Shift-JISより構造がシンプルで、文字列処理が容易です。主にUnix系システムとのデータ交換で利用されてきました。Windows でもサポートされていますが、Shift-JISほど広く利用されているわけではありません。現在ではUTF-8への移行が進んでいますが、一部のシステムやアプリケーションでは依然として利用されているため、その存在を認識しておく必要があります。
UTF-8 の特徴と利用例
UTF-8 は、Unicodeをエンコードした文字コードで、世界中のあらゆる文字を表現可能です。可変長であり、英数字は1バイト、日本語は3バイトで表現されるため、データサイズがShift-JISやEUC-JPよりも大きくなる傾向があります。しかし、国際的な標準として広く普及しており、異なる言語環境間でのデータ交換で問題が発生する可能性が低いため、現在では推奨される文字コードです。特に、Webアプリケーションや国際的なデータ交換を行うシステムでは、UTF-8の使用が必須となっています。
BOM(バイトオーダーマーク)の役割
BOM(Byte Order Mark)は、ファイルの先頭に付加される特別なバイト列で、ファイルの文字コードを識別するために使用されます。UTF-8などでは、BOMの有無によって処理が異なる場合があります。BOMの有無は、テキストエディタの設定などで制御できます。 BOM付きUTF-8とBOMなしUTF-8では、処理方法が異なる場合があるので注意が必要です。 特に、プログラムでファイルを読み込む際には、BOMの有無を考慮した処理を実装する必要があります。
文字コードの変換と注意点
異なる文字コード間でデータを変換する際には、文字化けが発生しないよう注意が必要です。適切な変換ツールやライブラリを使用し、変換処理を正確に行うことが重要です。また、変換時にデータロスが発生する可能性もあります。 変換前の文字コードと変換後の文字コードを明確に指定し、変換結果を検証する必要があります。 特に、複雑な文字を含むデータを変換する際には、十分なテストを行い、問題がないことを確認する必要があります。
| 文字コード | 特徴 | 利点 | 欠点 |
|---|---|---|---|
| Shift-JIS | 日本語環境で広く使われてきた可変長文字コード | コンパクト | UTF-8との互換性がない、文字列処理が複雑 |
| EUC-JP | Unix系システムとのデータ交換で使われてきた | 構造がシンプル | Shift-JISほど普及していない |
| UTF-8 | Unicodeをエンコードした国際標準の可変長文字コード | 世界中の文字を表現可能、国際的なデータ交換に適している | データサイズが大きくなる傾向がある |
Windowsの標準の文字コードは?
Windowsにおける文字コードの変遷
Windowsの初期バージョンでは、ANSIコードページと呼ばれる、地域ごとに異なる文字コードが使用されていました。これは、各国語に対応するために必要な文字の種類が異なっていたためです。しかし、グローバル化が進むにつれて、複数の言語を同時に扱う必要性が高まり、一つの文字コードで世界中の文字を表現できるUnicodeの必要性が高まりました。Windows NT以降のバージョンでは、Unicodeが標準として採用され始め、現在ではUTF-16 LEが中心的な役割を果たしています。
- 初期のWindowsでは、地域によってShift-JIS(日本)、EUC-KR(韓国)、Big5(台湾)など、様々なコードページが使用されていた。
- Unicodeの導入により、複数の言語を同時に扱うことが容易になった。
- UTF-16 LEは、Unicode文字を効率的に扱うための最適なエンコーディングとしてWindowsで採用された。
UTF-16 LE とUTF-8 の違い
UTF-8は、Unicode文字を可変長で表現する方式で、英数字は1バイト、漢字などの文字は複数バイトで表現されます。一方、UTF-16 LEは、Unicode文字を基本的に2バイトで表現します。UTF-8は、インターネット上で広く使用されており、可変長であるため、データサイズを節約できます。UTF-16 LEは、Windows内部処理において効率が良い反面、データサイズが大きくなる傾向があります。Windowsでは、ファイルの保存時にUTF-8を選択することも可能です。
- UTF-8は可変長なので、データサイズが小さくなる傾向がある。
- UTF-16 LEは固定長なので、処理速度が速い傾向がある。
- インターネット上ではUTF-8が広く使われているため、ウェブアプリケーション開発ではUTF-8の使用が推奨されることが多い。
コードページと文字化け
異なるコードページのテキストファイルを、間違ったコードページで開くと、文字化けが発生します。これは、文字コードが正しく解釈されないためです。例えば、Shift-JISで記述されたテキストファイルを、UTF-8で開くと、文字が正常に表示されません。Windowsでは、メモ帳などのテキストエディタで、ファイルの文字コードを指定して開くことができます。適切なコードページを選択することで、文字化けを回避できます。
- 文字化けは、異なる文字コードでエンコードされたファイルを、別の文字コードでデコードしようとした際に発生する。
- メモ帳などのテキストエディタでは、ファイルを開く際にエンコード方式を指定できる。
- 開発においては、使用する文字コードを明確に指定し、一貫性を保つことが重要である。
コマンドプロンプトにおける文字コード
Windowsのコマンドプロンプトでは、デフォルトの文字コードは、システムの地域設定によって異なります。通常は、システムのデフォルトのANSIコードページが使用されます。しかし、コマンドプロンプトの設定を変更することで、UTF-8などの他のコードページを使用することも可能です。 chcpコマンドを使って、コードページを変更することができます。特定の文字コードが必要な場合は、このコマンドを用いることで対応できます。
- コマンドプロンプトの文字コードは、システムの地域設定に依存する。
chcpコマンドで、文字コードを変更することができる。- 特定の言語や文字を正しく表示するために、コードページを変更することが必要となる場合がある。
アプリケーションと文字コード
アプリケーションによっては、独自の文字コードを使用しているものもあります。そのため、アプリケーションの仕様を確認する必要があります。特に、古いアプリケーションでは、Unicodeに対応していないものが存在します。新しいアプリケーションでは、UTF-8やUTF-16に対応しているものが多くなっていますが、万が一文字化けが発生した場合は、アプリケーションの設定を確認したり、開発元に問い合わせる必要がある場合があります。
- アプリケーションごとに使用する文字コードが異なる場合がある。
- アプリケーションの設定で文字コードを指定できる場合がある。
- 文字化けが発生した場合は、アプリケーションの仕様を確認する必要がある。
Windows11のデフォルト文字コードは?
Windows 11におけるUTF-8の役割
Windows 11では、UTF-8がデフォルトの文字コードとしてシステム全体で広く採用されています。これは、世界中の様々な言語の文字を適切に表示・処理するために不可欠な役割を果たしています。 しかし、全てのコンポーネントが完全にUTF-8に準拠しているとは限らないため、文字化けなどの問題が発生する可能性も依然として存在します。
- システムファイルの大部分はUTF-8でエンコードされています。
- 新しいアプリケーションはUTF-8をサポートしているものがほとんどです。
- コマンドプロンプトやPowerShellなどのコンソールアプリケーションもUTF-8に対応しています(設定が必要な場合があります)。
Shift-JISとの共存
古いアプリケーションや、日本国内で開発されたレガシーシステムでは、Shift-JISが文字コードとして使用されているケースが多く見られます。Windows 11は後方互換性を考慮し、これらのシステムとの連携を可能にしていますが、UTF-8との間で文字コード変換が必要になる場合があります。この変換処理は、場合によっては文字化けの原因となる可能性があります。
- Shift-JISは主に日本語の文字を扱うために設計されました。
- 古いWindowsアプリケーションやゲームなどでShift-JISが使用されていることがあります。
- Shift-JISとUTF-8間の変換は、適切な設定やライブラリを用いることで行えます。
文字コードの指定方法
特定のアプリケーションや処理では、文字コードを明示的に指定する必要がある場合があります。例えば、テキストファイルを作成する際や、外部システムとデータ交換を行う際には、適切な文字コードを指定することで、文字化けを防ぐことができます。多くのアプリケーションでは、設定画面などで文字コードを指定できるようになっています。
- テキストエディタでは、保存時の文字コードを指定できます。
- プログラミング言語では、文字コードを扱うための関数やライブラリが用意されています。
- コマンドラインツールでも、文字コードを指定するオプションが用意されている場合があります。
文字化けの対処法
Windows 11において文字化けが発生した場合、原因を特定することが重要です。アプリケーションの設定を確認したり、ファイルの文字コードを調べたりすることで、問題解決の糸口を見つけることができます。必要に応じて、文字コード変換ツールを使用することも有効な手段です。
- 文字化けしているファイルの文字コードを特定します。
- 適切な文字コード変換ツールを用いて、文字コードを変換します。
- アプリケーションの設定で、文字コードを修正します。
地域設定と文字コード
Windows 11の地域設定は、文字コードの設定に影響を与える可能性があります。地域設定を変更することで、システムが使用する文字コードや日付・時刻の表示形式などが変わる場合があります。文字化けが発生した場合、地域設定を確認してみるのも有効です。
- 地域設定は、コントロールパネルから変更できます。
- 地域設定を変更すると、日付、時刻、通貨などの表示形式も変更されます。
- 地域設定を変更する際は、システム全体への影響を考慮する必要があります。
Windowsで文字コードを調べるには?
Windowsで文字コードを調べる方法
Windowsで文字コードを調べる方法はいくつかあります。ファイルの種類や状況によって最適な方法が異なります。最も基本的な方法は、メモ帳などのテキストエディタでファイルを開き、エンコード情報を確認することです。多くのエディタは、ファイルを開いた際に文字コードを自動的に検出し、メニューやステータスバーに表示します。しかし、自動検出が失敗する場合もあります。そのような場合は、ファイルのプロパティを確認したり、専用のツールを使用したりする必要があります。
ファイルの種類から推測する
ファイルの種類から、使用されている文字コードをある程度推測することができます。例えば、.txtファイルは通常UTF-8またはShift-JISが使われますが、必ずしもそうとは限りません。.csvファイルも同様に、UTF-8、Shift-JIS、CP932など様々な文字コードが使用される可能性があります。ファイルの拡張子だけでは判断できない場合も多いので、他の方法と併用することが重要です。
- 拡張子がtxtの場合、UTF-8またはShift-JISの可能性が高い。
- 拡張子がcsvの場合、UTF-8、Shift-JIS、CP932などが考えられる。
- 拡張子だけでは文字コードを特定できない場合が多いので注意が必要。
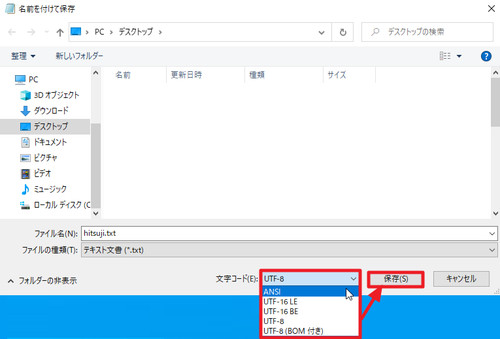
メモ帳で文字コードを確認する
Windows標準のメモ帳は、ファイルを開いた際に文字コードを自動的に検出しようとします。しかし、正確性に欠ける場合があります。メモ帳でファイルを開き、「ファイル」→「名前を付けて保存」を選択すると、エンコードの種類を選択する画面が表示されます。この画面で、ファイルの実際の文字コードを確認することができます。ただし、メモ帳はBOM(Byte Order Mark)の存在に依存するため、BOMがないファイルの場合、正しく文字コードを認識できない可能性があります。
- メモ帳でファイルを開く。
- 「ファイル」→「名前を付けて保存」を選択する。
- エンコーディングの種類を確認する(自動検出の場合、正確性に欠ける可能性がある)。
ファイルのプロパティを確認する
ファイルのプロパティにも、場合によっては文字コードに関する情報が含まれていることがあります。ファイルを選択し、右クリックして「プロパティ」を選択すると、ファイルの詳細情報が表示されます。ただし、文字コードが直接表示されることは少ないため、この方法だけでは文字コードを特定できないことが多いです。他の方法と併用する必要があります。
- ファイルを右クリックする。
- 「プロパティ」を選択する。
- 詳細情報を確認する(文字コードの情報は直接表示されないことが多い)。
Notepad++などのテキストエディタを使用する
メモ帳よりも高機能なテキストエディタ、例えばNotepad++などは、ファイルの文字コードをより正確に検出することができます。Notepad++では、ステータスバーにファイルの文字コードが表示されます。また、エンコードの変換機能も備えているため、必要に応じて文字コードを変換することも可能です。多くの高度なエディタが同様の機能を提供します。
- Notepad++などのテキストエディタでファイルを開く。
- ステータスバーで文字コードを確認する。
- 必要に応じて文字コードを変換する。
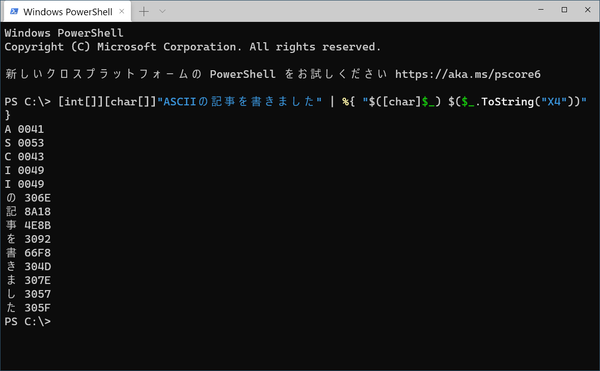
コマンドプロンプトを使う
コマンドプロンプト(cmd.exe)やPowerShellを使うことで、ファイルの文字コードをより詳細に調査できます。例えば、`file`コマンド(一部の環境ではインストールが必要)を使用すると、ファイルの種類だけでなく、文字コードに関する情報も得られる可能性があります。ただし、この方法はコマンドライン操作に慣れているユーザー向けです。コマンドの使用方法を理解する必要があります。
- コマンドプロンプトまたはPowerShellを開く。
file [ファイルパス]コマンドを実行する。- 出力結果から文字コードに関する情報を確認する(コマンドの利用には知識が必要)。
文字コードを『utf-8』に変更するにはどうすればいいですか?
文字コードをUTF-8に変更する方法
文字コードをUTF-8に変更する方法は、使用するアプリケーションや環境によって異なります。一般的には、以下の手順で行います。
テキストエディタの場合
テキストエディタでファイルを開いた後、エンコードの設定を変更します。多くのエディタでは、「ファイル」メニューや「設定」メニューの中に「エンコード」や「文字コード」といった項目があります。そこで、UTF-8を選択して保存すれば、文字コードがUTF-8に変更されます。具体的な手順はエディタによって異なりますが、一般的には以下のようになります。
- 対象のテキストファイルを開きます。
- メニューから「ファイル」>「保存」または「ファイル」>「名前を付けて保存」を選択します。
- エンコーディング(文字コード)のリストからUTF-8を選択し、「保存」をクリックします。
ウェブブラウザの場合
ウェブブラウザで文字コードを変更することはできません。ウェブサイトのソースコード自体がUTF-8で保存されていない場合、ブラウザは正しく表示できない可能性があります。ウェブサイトの管理者にUTF-8で保存するように依頼する必要があります。ウェブサイトのHTMLファイルを直接編集できる場合は、タグをセクションに追加することで、UTF-8で表示させることができます。
- ウェブサイトのソースコードにアクセスします。
セクション内にタグを追加します。- 変更を保存し、ウェブサイトを更新します。
プログラミング言語の場合
プログラミング言語では、使用するライブラリや関数によって異なります。多くの言語では、ファイルを開く際に文字コードを指定できます。例えば、Pythonではopen()関数にencoding='utf-8'引数を指定します。ファイルを読み書きする際に適切なエンコーディングを指定することが重要です。それぞれのプログラミング言語のドキュメントを参照してください。
- ファイルを開く際に、エンコーディングを指定します。
- ファイルの読み書き処理を行います。
- エラー処理を実装します。
データベースの場合
データベースの場合、データベースシステムの設定を変更する必要があります。具体的な手順はデータベースの種類によって異なりますが、一般的にはデータベースの文字コード設定を変更することでUTF-8に対応できます。データベース管理システムのドキュメントを参照して、適切な設定変更を行ってください。間違った設定はデータの破損につながる可能性があるので注意が必要です。
- データベース管理システムにログインします。
- データベースの設定を変更します。
- 変更を適用します。
コマンドラインツールの場合
コマンドラインツールを使用する場合は、使用するコマンドによって異なります。例えば、`iconv`コマンドを使用することで、ファイルの文字コードを変換できます。`iconv -f 元の文字コード -t UTF-8 ファイル名` のように使用します。元の文字コードを正しく指定することが重要です。間違った文字コードを指定すると、データが壊れる可能性があります。
iconvコマンドを使用します。- 元の文字コードと変換後の文字コードを指定します。
- 変換後のファイル名も指定します。
詳しくはこちら
Windowsの文字コードの種類は何ですか?
Windowsは、Shift JIS、UTF-8、Unicodeなど、複数の文字コードをサポートしています。使用する文字コードは、システムの言語設定やアプリケーションによって異なります。一般的に、日本語環境ではShift JISが従来から多く使われてきましたが、近年はUTF-8への移行が進んでいます。UTF-8は世界共通の文字コードであり、様々な言語の文字を扱う際に互換性の問題が少ないためです。
文字化けの原因は何ですか?
文字化けは、ファイルの文字コードと、それを表示するアプリケーションの文字コード設定が一致していない場合に発生します。例えば、Shift JISで保存されたファイルがUTF-8で表示されると、文字化けが起こります。また、ファイルのBOM(バイトオーダーマーク)の有無も影響することがあります。BOMは文字コードの種類を示す情報ですが、アプリケーションによっては正しく認識されない場合もあります。
Shift JISとUTF-8の違いは何ですか?
Shift JISは、日本語を主に扱うために設計された文字コードで、2バイト文字を使用します。一方、UTF-8は、世界中の様々な言語に対応できる可変長文字コードで、1バイトから4バイトの文字を使用します。UTF-8は、グローバル化に対応するために広く利用されており、インターネット上では標準的な文字コードとなっています。Shift JISは、日本の古いシステムとの互換性を維持するために使用されることが多いです。
Windowsで文字コードを変更するにはどうすればいいですか?
文字コードの変更方法は、アプリケーションによって異なります。テキストエディタなどでは、保存時に文字コードを選択できます。メモ帳などの場合、エンコードの設定を変更することで文字コードを切り替えることができます。また、システム全体の文字コードを変更する場合は、地域と言語の設定から変更できますが、システム全体に影響を与えるため、注意が必要です。予期せぬ動作を引き起こす可能性があるため、変更する際は十分に理解した上で実行しましょう。